AWS Karpenter Spot 中断优化
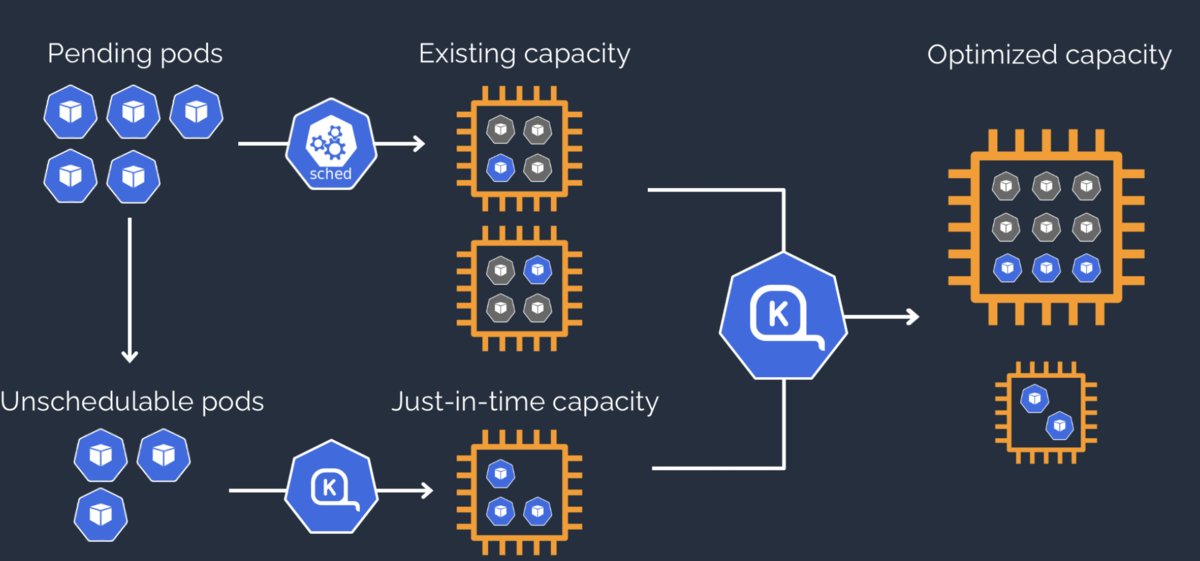
spot 实例价格虽然相比于正常的便宜一倍之多,但是也会面临随时中断的情况,而新Pod从机器启动到进入ready,往往又要数分钟。即使对业务进行了针对性改造,适应随时Pod替换的场景,也无法百分百确保不会有影响,但Spot从收到中断信号,会留2分钟的时间给用户处理资源回收,目前主流的是依赖 karpenter 进行管理,如申请机器,处理中断等,但karpenter处理 spot 中断也是很干脆的直接驱逐所有Pod,难免影响可用率,那我们在这两分钟能不能在做点什么? —–注意:本文只是初步代码验证,笔者尚未在生产环境中使用
一、思路
收到 Spot 中断信号后,已经知道哪些 Pod 会被驱逐,是否可以提前启动对应的Pod,等过了90s后,再驱逐老Pod?如此便可进可能的将新Pod启动时间降到最低!
二、关键技术点
2.1 Spot 中断独立karpenter运行
首先我们不能依赖 karpenter 的 Spot 中断处理,需要单独剥离给我们自己的控制器处理,但是集群的节点扩缩容又非常依赖karpenter,我们可以创建一个空的sqs,将karpenter的 sqs 换到该SQS,再将原本karpenter的SQS给我们自己的控制器使用 注意:这样会导致karpenter 无法记录被中断的 spot 型号,下次还是会去申请该型号,但实际使用影响有限
2.2 如何提前启动对应Pod 并不被副本控制器缩容回去
我们可以先启动一个「游离态」的Pod,该Pod会去除掉原本 Selector 标签,这样就无法被 replicaset 控制器接管,也就不会被自动缩容
2.3 游离 Pod 如何实现替换
先下线Pod,然后通过 webhook 捕捉Pod Pending 请求,并将游离态的 Pod 标签改了回来,再拒绝掉本次的 Pod创建
三、代码实现
spot 的处理可以参考karpenter 的代码,较为简单,此处不展开
3.1 启动游离Pod
下面的伪代码,当有节点要被驱逐的时候,会先将该节点标记为「不可调度」,再复制所有节点上的Pod,并移除掉所有的标签,并启动一个协程,在特定时间后,会执行移除老Pod所有的标签,这样该Pod就从deployment中被移除了(endpoint也会),新的流量将不会再进来,老的请求还可以继续处理
func (c *PodController) HandleNodeDrain(nodeName string) error {
pods, err := c.client.CoreV1().Pods("").List(context.Background(), metav1.ListOptions{
FieldSelector: "spec.nodeName=" + nodeName,
})
if err != nil {
return err
}
for _, pod := range pods.Items {
// 排除daemonset的Pod
// Skip DaemonSet pods
if pod.OwnerReferences != nil {
for _, owner := range pod.OwnerReferences {
if owner.Kind == "DaemonSet" {
continue
}
}
}
// 创建替代 Pod
replacementPod, err := c.createReplacementPod(&pod)
if err != nil {
hlog.Errorf("Failed to create replacement pod for %s: %v", pod.Name, err)
continue
}
hlog.Infof("Created replacement pod %s for %s", replacementPod.Name, pod.Name)
// 生成部署标识键
key := queue.GetDeploymentKeyFromLabels(pod.Labels, pod.Namespace)
// 存储到 Map
c.podMap.Store(key, queue.PodReplacement{
OriginalPod: pod.Name,
ReplacementPod: replacementPod.Name,
Namespace: pod.Namespace,
Labels: pod.Labels,
})
// 60秒后移除原 Pod 标签
go func(p corev1.Pod, key string) {
time.Sleep(60 * time.Second)
hlog.Infof("Removing labels from pod %s", p.Name)
err := c.removePodLabels(&p)
if err != nil {
hlog.Errorf("Failed to remove labels from pod %s: %v", p.Name, err)
}
}(pod, key)
}
return nil
}
func (c *PodController) createReplacementPod(originalPod *corev1.Pod) (*corev1.Pod, error) {
// 从原始 Pod 名称中提取命名模式
// 典型的 Deployment 生成的 Pod 名称格式是: {deployment-name}-{random-suffix}
podName := originalPod.Name
// 去掉最后的随机后缀,保留前缀部分
// 通常后缀是 "-xxxxx" 形式,我们可以找到最后一个"-"
lastDashIndex := strings.LastIndex(podName, "-")
podPrefix := podName
if lastDashIndex > 0 {
podPrefix = podName[:lastDashIndex]
}
// 创建替代 Pod
newPod := &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
// 使用相同的命名前缀,让 K8s 生成随机后缀
GenerateName: podPrefix + "-",
Namespace: originalPod.Namespace,
// 故意不设置标签
Annotations: originalPod.Annotations,
},
Spec: originalPod.Spec,
}
// 清除一些不需要的字段
newPod.Spec.NodeName = ""
// 移除可能导致问题的字段
newPod.ResourceVersion = ""
newPod.UID = ""
newPod.OwnerReferences = nil // 清除 OwnerReferences 避免控制器干扰
return c.client.CoreV1().Pods(newPod.Namespace).Create(context.Background(), newPod, metav1.CreateOptions{})
}
func (c *PodController) removePodLabels(pod *corev1.Pod) error {
pod.Labels = nil
_, err := c.client.CoreV1().Pods(pod.Namespace).Update(context.Background(), pod, metav1.UpdateOptions{})
return err
}3.2 如何将Pod加回来
我们通过一个 mutating webhook 来实现: 当上一步的协程将老Pod标签移除后,会触发一次扩容操作,我们通过webhook拦截本次操作,并将对应新Pod的标签改成正确标签,最后拒绝Pod的创建。此时deployment就恢复正常了
type PodMutatingWebhook struct {
client client.Client
decoder admission.Decoder
podMap *queue.PodReplacementMap
}
// NewPodMutatingWebhook creates a new PodMutatingWebhook
func NewPodMutatingWebhook(c client.Client, m *queue.PodReplacementMap) *PodMutatingWebhook {
return &PodMutatingWebhook{
client: c,
podMap: m,
}
}
// Handle handles admission requests.
func (w *PodMutatingWebhook) Handle(ctx context.Context, req admission.Request) admission.Response {
if req.Operation != admissionv1.Create {
return admission.Allowed("not a create operation")
}
pod := &corev1.Pod{}
err := w.decoder.Decode(req, pod)
if err != nil {
return admission.Errored(http.StatusBadRequest, err)
}
// 从 Pod 标签生成部署标识键
key := queue.GetDeploymentKeyFromLabels(pod.Labels, pod.Namespace)
// 检查是否有替换 Pod
replacement, ok := w.podMap.Load(key)
if !ok {
return admission.Allowed("no replacement pod available for " + key)
}
// 获取替换 Pod
replacementPod := &corev1.Pod{}
err = w.client.Get(ctx, client.ObjectKey{
Namespace: replacement.Namespace,
Name: replacement.ReplacementPod,
}, replacementPod)
if err != nil {
hlog.Errorf("Failed to get replacement pod: %v", err)
return admission.Errored(http.StatusInternalServerError, err)
}
// 更新替换 Pod 的标签
replacementPod.Labels = replacement.Labels
// 使用过一次后从 Map 中删除
w.podMap.Delete(key)
// 创建 patch
marshaled, err := json.Marshal(replacementPod)
if err != nil {
return admission.Errored(http.StatusInternalServerError, err)
}
hlog.Infof("finished pod relacement, new pod name: %s", replacementPod.Name)
return admission.PatchResponseFromRaw(req.Object.Raw, marshaled)
}四、总结
如果你的Pod 从Pending-> Running时间在2分钟以内,是可以做到毫秒级别的切换的,将影响降低到最小!
注:
详细代码可见:https://github.com/ox-warrior/floz/tree/test-spot